A Complete Guide to Running a Code Plagiarism Check


Computer technology enrollments are surging globally, putting immense pressure on educators to grade large quantities of complicated submissions. In this environment, maintaining academic strength is a critical challenge. Unlike standard documents, supply rule uses rigid syntactical rules, which could make unique between respectable venture and outright copying problematic for the inexperienced eye.
As digital repositories and AI guidance methods become ubiquitous, the techniques for determining source code plagiarism in scholar tasks must evolve. Listed below are the absolute most frequently asked questions concerning the recognition of software plagiarism, reinforced by the mechanics of how contemporary analysis works.
How common is signal plagiarism in higher knowledge?
Academic dishonesty in development programs is widely regarded a significant issue. While accurate global statistics vary, various departmental studies claim that preliminary pc technology classes frequently see larger costs of similarity in submissions in comparison to other disciplines. That is partly as a result of goal nature of development; you can find often limited ways to solve a beginner-level problem efficiently. Nevertheless, when fifty pupils send tasks with identical logic structures and only trivial improvements, mathematical likelihood implies plagiarism rather than coincidence.
Why is manual evaluation insufficient for finding copied signal?
Relying on human review is significantly unrealistic as a result of level of data. A teaching assistant grading 100 projects might discover if two pupils sitting next together send identical files. But, they're unlikely to catch students who replicated a submission from a previous year or person who seriously altered the aesthetics of the signal while maintaining the key reasoning intact. Cognitive weakness sets in rapidly, creating handbook cross-referencing of each and every distribution against every other distribution mathematically impossible for a human to do in an acceptable timeframe.
What are the common techniques pupils use to disguise plagiarism?
To evade recognition, pupils usually employ obfuscation techniques. The most typical efforts contain:
• Renaming Factors: Adjusting int depend to int d or int number.
• Adding Remarks: Inserting needless remarks to change the file measurement or point count.
• Reordering Operates: Moving separate functions about within the file.
• Whitespace Treatment: Introducing added lines or spaces.
While these improvements adjust the textual look of the signal, they seldom change the underlying algorithmic fingerprint.
How do automatic methods identify plagiarism despite these improvements?
Professional detection computer software moves beyond simple text matching. Instead of evaluating the text line-by-line, advanced algorithms tokenize the source code. The application switches the program in to a flow of tokens or an Abstract Syntax Tree (AST). This technique pieces out variable names, comments, and formatting, making behind the structural skeleton of the logic.
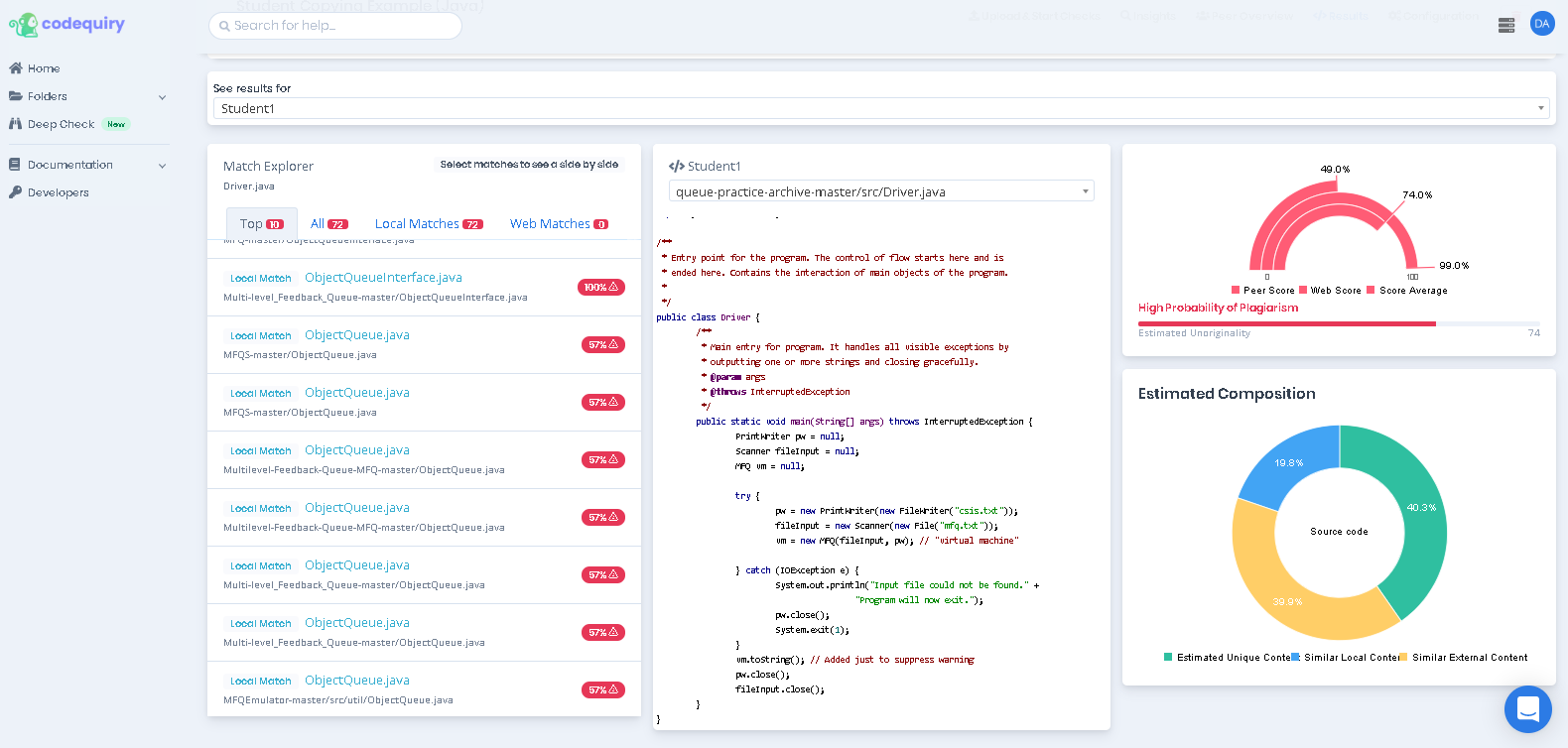
By evaluating these structural fingerprints, teachers may recognize code plagiarism in student tasks even though the text appears completely different. If the reason movement, decision woods, and loop structures fit perfectly between two pupils, the likelihood of independent creation is near zero.
Can detection pc software separate between legitimate rule and plagiarism?
Computerized instruments provide a likeness score, but they cannot produce the final judgment. They act as a forensic support for the instructor. High likeness can sometimes derive from boilerplate code provided by the teacher or normal selection usage. Therefore, the goal of the methods is to flag statistically improbable characteristics for human review, ensuring that the final choice regarding academic strength stays in the fingers of the educator.